随着AI的发展,Prompt 提示词成为了必须要掌握的技巧,如何更好的提问直接影响AI输出内的内容。因此也逐渐演化出了一个新的学科,提示工程。提示工程主要应用于开发和优化提示词,帮助用户有效的与AI交互,让大语言模型在各种场景和领域更好应用和工作。
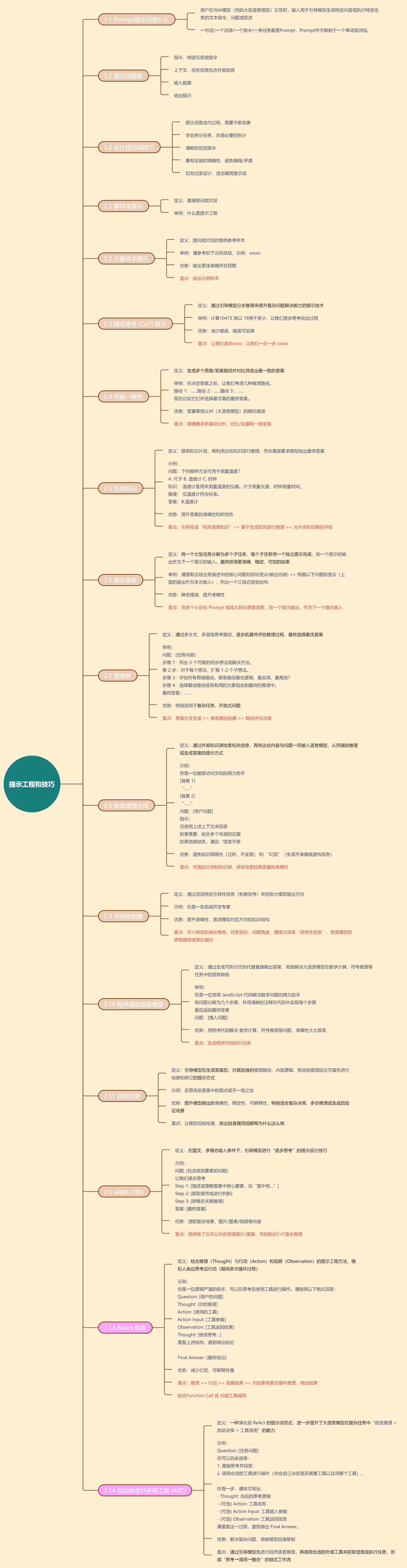
一、基础内容
1.1 Prompt提示词是什么
指用户在与AI模型(例如大型语言模型)交互时,输入用于引导模型生成特定内容或执行特定任务的文本指令、问题或陈述。简单来说,通过清晰地表达用户意图,引导模型产生有价值和相关的回应。
一句话/一个词语/一个指令/一条任务都是Prompt,Prompt并不限制于一个单词或词组。
1.2 提示词要素
提示词可以包含以下任意要素:
- 指令: 想要模型执行的特定任务或指令
- 上下文:包含外部信息或额外的上下文,引导语言模型更好地响应
- 输入数据:用户输入的内容或问题
- 输出指示:指定输出的类型或格式
这里简单解释一下上下文,这个词语可能有人会有疑问。在交流或信息处理中,当前对话或事件所处的背景环境,包括信息、相关场景、共同知识。帮助理解当前内容的真正含义,避免歧义或误解。
举例
你记住,一个半小时是三个半小时
太空有空间站,太挤就没有空间站
你记住,有你好果子吃,和没你好果子吃是一个意思
在中国,二五一十是对的,一五一十也是对的
豆腐一块两块等于两块一块
那个啥把那个啥给那个啥了,到底啥是什么
以前喜欢一个人,现在喜欢一个人
以前没钱吃泡面,现在没钱吃泡面
以前谁也看不上 现在谁也看不上
这些话你都能理解,是因为我们有共同的知识和语言体系,阅读时也能在大脑内构造出对应语境和场景,那我们拥有的知识和语言体系,就是上下文。
1.3 设计提示词技巧
1.3.1 提示词是迭代过程
- 设计提示是一个迭代过程,需要大量实验才能获得最佳结果,从简单的提示词开始,并逐渐添加更多元素和上下文。过程中不断迭代你的提示词是至关重要的。
1.3.2 学会拆分任务
- 当你有一个大任务时,可以尝试将任务分解为更简单的子任务,逐步完成,而不是让AI一次性输出内容。
1.3.3 清晰的设定指令
你可以使用命令来指示模型执行各种简单任务,举例:”写入”、”分类”、”总结”、”翻译”、”排序”等,为各种任务设计有效的提示
有人建议将指令放在提示的开头,也有人则建议是使用像”###”这样的分隔符来分隔指令和上下文,目前来看采用的 “###”形式较多
1 | ### 指令 ### |
1.3.4 要有足够的明确性
- 要非常具体地说明你希望执行的指令和任务。提示越具有描述性,结果越好,尤其是对生成结果或风格有要求时。不存在什么特定的词元或关键词带来确定性的更好结果(这个很重要,没有最好最正确)。更重要的是具有良好格式和描述性的提示词。
1.3.5 根据需求,适当精简提示词
- 提示词长度是有限制的,包含太多不必要的细节不一定是好的方法
- 比如:从文本中提取特定信息的提示
1 | 提取以下文本中的地名 |
上面的提示方法,在处理非共识性内容,具有自己特定预期的时候,较为合适,但是对于共识性内容,反而更直接一些会更好,避免陷入”提示上过于聪明”陷阱,从而创造出不明确的描述。
- 比如:什么是提示工程?
- 这是一个具有共识通识的概念,如果加太多提示,可能最后输出预期有所偏离。
1 | 什么是提示工程? |
上面这些是一些基础性的技巧,是必备的知识前提内容,下面便是有专业术语表达和论文支撑和数据验证的技术性的内容,很多内容其实并不复杂,甚至你可能在不经意间进行了应用。
二、提示技术
2.1 零样本提示
2.1.1 常规零样本提示
你直接提问,要求模型给出一个回答,没有提供任何关于提问示例或示范内容。
最终的输出结果,主要受到任务的复杂性和知识专业度,以及模型自身能力的影响。如果任务过于复杂或者模型的能力一般,一般很难得到预期答案。
提示词举例
1 | 什么是提示词工程? |
2.1.2 零样本 CoT(链式思考) 提示
将”让我们逐步思考”添加到原始提示中,我们在提示词里增加了,让我们一步一步的分析,可以看下面示例:
该测试在本地的模型可以可以,在线版模型一般不会犯这种错误

2.1.3 提示词举例
1 | // 零样本 |
2.2 少量样本提示
论文:https://arxiv.org/pdf/2302.13971
2.2.1 设计技巧
- 样本代表性与多样性
- 输入-输出结构显式对齐
- 错误样本反哺(负样本)
- 元指令嵌入
1 | ====== 多样性 |
2.2.2 常规少量样本提示
通过提供示例(示范)样本/结构,让大语言模型,给出较为合理的输出。
以下面的读后感来说,我如果只提供帮我完成一份小王子读后感一句话提示词。输出的内容,可能是没有子标题概念的通篇读后感,内容结构也完全随机产生,结果符合要求的可能性会很低。
提示词举例
1 | // 通用编写格式 |
2.2.3 少量样本 CoT 提示
与零样本一样,少量样本提示也可以结合链式思考,让结果更准确可靠
2.2.4 提示词举例
1 | 示例1: |
2.3 链式思考 (CoT) 提示
链式思考(Chain-of-Thought, CoT)提示: 是一种通过引导模型分步推理来提升复杂问题解决能力的提示技术。核心思想是让模型像人类一样展示推理过程,而非直接输出最终答案。
论文:https://arxiv.org/abs/2201.11903
2.3.1 设计技巧
- 明确触发词:必须清晰要求分步推理(”逐步推导”展示完整推理过程”请分步骤解释”)避免模糊指令(”仔细思考”),直接使用:让我们一步步推理。
- 任务适配结构:(数学:强调公式→代入→计算→验证;因果分析:第一步的原因是…,这导致…)
- 控制步骤粒度:拆分子问题(先解决X部分,再分析Y部分)
- 少样本示例设计:提供少量必要的样本
- 元指令强化:每步需基于上一步结果,在最后一步验证答案合理性,若出现矛盾,回溯到第N步检查
2.3.2 CoT 的特点
- 减少错误:通过中间步骤验证逻辑,避免”直觉性错误”
- 适合复杂任务:在算术、推理、规划等任务中表现优于直接提问
- 降低思维跳跃:避免模型因”一步到位”而忽略细节
- 错误可追溯:通过中间步骤定位错误来源
2.3.3 适用场景
- 数学计算:多步运算或应用题
- 逻辑谜题:如”谁养鱼”类经典推理题
- 现实规划:例如时间安排、资源分配
- 因果推理:分析事件的原因和结果
2.3.4 提示词举例
1 | xxxxx,让我们逐步思考 |
我们在前一篇提示词教程里,知道了几个关键提示词技术,
零样本提示和零样本CoT,少量样本提示和少量样本CoT,链式思考提示(CoT),这次我们在学习一些其他的提示技巧。
2.4 自我一致性
通过少样本 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。简单来说 通过生成多条独立推理路径并投票选择最一致答案,显著降低大语言模型(LLM)的随机错误。
论文:https://arxiv.org/pdf/2203.11171
包含三个步骤
- 使用思维链 (CoT) 提示,提示语言模型
- 生成一组多样化的推理路径和结果
- 在最终答案集中投票选择最一致的答案
核心准则
- 问题:LLM 在复杂推理(逻辑题)中,相同提示多次运行可能输出不同答案(因采样随机性)
- 洞察:错误答案的推理路径往往不一致,但正确答案的路径会收敛
- 解法:生成多条推理链 → 交叉验证答案一致性 → 选最高频答案为最终结果
- 类比:让学生多次验算同一题,如果3次独立计算都得 42,而只有1次得 35,则 42 更可信
2.4.1 设计技巧
- 清晰定义任务与约束:明确目标,规则边界,格式结构
- 引入上下文与记忆:提供任务所需的关键信息,减少模型”自由发挥”
- 显式要求一致性:提示词中加入明确的指令,”保持逻辑一致”、”避免前后矛盾”、”请进行自我验证”
- 分步推理与自我验证:要求模型”一步一步地思考”,要求关键问题验证自己的推理或假设是否一致
- 多次采样与投票/聚合:让模型对同一个问题生成多个可能的回答,然后从中选出最一致或最频繁出现的答案/元素。
- 角色与风格锚定:需要扮演的角色的背景、知识领域、语言风格、立场等,并要求其在所有输出中严格遵守。
- 位置很重要: 将关键约束(一致性要求/角色设定)放在提示词的开头或结尾更有效
- 强调关键词: 使用大写,星号
**,引号等强调关键词 - 组合策略: 通常组合多种策略才能达到最佳效果(如
清晰定义任务+显式要求一致+分步推理) - 迭代优化: 观察模型的输出,找出不一致的地方,在提示词中增加针对性的约束或说明。
2.4.2 为什么需要
LLM 在复杂推理中存在两大瓶颈
- 随机性误差:单次采样可能因”运气差”选中错误推理链
- 路径依赖错误:若第一步推错,后续步骤可能延续错误(CoT的缺陷)
2.4.3 应用场景
- 数学计算(方程求解、应用题)
- 逻辑推理(谜题、因果推断)
- 多跳问答(需结合多个事实的QA)
- 代码生成(多方案择优)
2.4.4 提示词举例
1 | 请用链式思考(逐步推理)解决以下问题,并给出最终答案。 |
2.5 生成知识
生成知识(Generated Knowledge,GK)是通过背景知识(用户提供或AI生成),回答复杂问题的提示工程技术。核心:提供知识片段,再利用这些知识进行推理,而非直接要求模型给出最终答案。
论文:https://arxiv.org/pdf/2110.08387
核心准则
- 单步推理拆解为 “知识创造 → 知识应用”,模仿人类”先查资料再分析”的思考方式
2.5.1 设计技巧
- 知识类型精准定位
1 | ## 知识定位声明 |
- 条件约束法
1 | ## 约束条件(必填) |
- 认知链生成机制
1 | ## 生成逻辑 |
- 自洽验证强化
1 | ## 验证规则(生成后自动执行) |
2.5.2 为什么需要
LLM 存在知识边界(训练数据截止)和知识固化(无法主动更新)
- 直接提问:模型可能依赖过时/模糊的记忆,导致错误
- 生成知识技术:强制模型先输出相关知识,再基于此推理,提升答案的准确性和时效性
1 | // 输入 |
2.5.3 应用场景
- 开放域问答
- 科学解释
- 创意生成
- 争议话题分析
2.5.4 提示词举例
1 | # 阶段1:知识生成 |
2.6 提示串联
为解决过于复杂或需要多步骤/多模型/多工具协作的任务,将一个庞大或复杂的任务拆分成一系列更小、更简单的子任务(”链”上的节点),然后按顺序依次执行这些子任务,前一个任务的输出作为后一个任务的输入,这就是所谓的提示串联(也叫链式提示,prompt chaining)。这也是AI工作流/Agent智能体的核心
技巧文档:https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/chain-prompts
核心内容
- 任务拆解 → 提示词编排 → 状态传递 → 错误防御
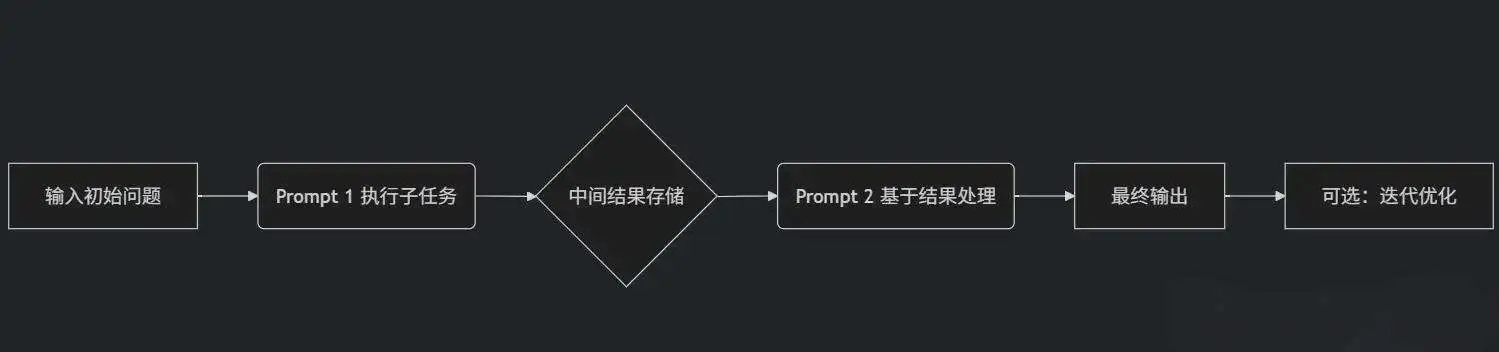
2.6.1 设计技巧
任务分解器
- 将大目标拆解为顺序执行的原子任务
- 例:撰写行业报告 1.数据收集 2.分析趋势 3.生成结论
提示词模板库
- 预置针对不同子任务的优化提示
1 | 分析以下文本:{input_text} |
状态传递机制
- 将前序输出结构化后注入后续提示
- 例:上一步的JSON结果 → 作为变量插入下一步提示
错误处理模块
- 检测异常输出并触发重试/人工干预
2.6.2 为什么需要
| 问题 | 传统单提示 | 提示词串联 |
|---|---|---|
| 任务复杂度 | 只能处理简单任务 | 可处理多步骤、跨领域复杂任务 |
| 模型能力局限 | 单次调用易出错/遗忘上下文 | 分步执行,降低单点失误风险 |
| 外部工具整合 | 难以结合API/数据库/计算工具 | 无缝衔接外部工具形成自动化流水线 |
2.6.3 应用场景
- 智能客服系统:用户问题 → 分类 → 知识库检索 → 生成回答 → 满意度预测
- 自动报告生成:原始数据 → 数据清洗 → 趋势分析 → 洞察提炼 → 生成PPT大纲
- 代码助手:需求描述 → 生成伪代码 → 编写具体函数 → 单元测试生成 → 调试建议
- 学术研究:论文PDF → 关键信息提取 → 生成综述 → 提出创新点 → 写作优化
- 短视频创作:热点话题 → 剧本生成 → 分镜设计 → 文案优化 → 自动字幕生成
- 决策支持:市场数据 → SWOT分析 → 风险评估 → 生成策略选项 → 可行性评分
- Agent智能体搭建
- AI工作流搭建
2.6.4 提示词举例
1 | 提示任务1-输入 |
如果该行为在扣子,n8n等工作流平台,那就是前后节点之间的连线,让任务1的输出,作为任务2的输入
2.7 思维树
思维树(Tree of Thoughts,ToT) 框架,是一种突破链式思维(CoT)的线性限制,引入树状结构进行多路径探索和回溯的复杂推理框架。
论文:https://arxiv.org/abs/2305.10601
论文:https://arxiv.org/abs/2305.08291
核心内容
模拟人类解决复杂问题时的”头脑风暴”过程——生成多种可能的思路(分支),评估它们的可行性,保留有潜力的路径继续深入探索,必要时回溯尝试其他路径,最终找到最优解。
| 组件 | 作用 | 示例(写小说) |
|---|---|---|
| 思维分解 | 将问题拆解成多个”思维单元” | 拆解为:主题→主角设定→世界观→核心冲突→结局 |
| 思维生成器 | 当前思维节点,生成多个下一步思路 | “主题”节点:AI反抗人/ AI与人共生/ AI自我怀疑 |
| 状态评估器 | 对每个生成的”思维”评分,判断质量 | AI觉醒7分/AI共生8分 |
| 搜索算法 | 决定如何遍历树:广度优先(BFS)/深度优先(DFS)/束搜索(Beam Search)等 | 保留当前最优的2个分支 |
| 回溯与整合 | 合并可行路径,或在死路时回溯到父节点尝试其他 | 将”共生”路径下的世界观+冲突整合成完整大纲 |
2.7.1 设计技巧
- 问题分解:将复杂问题分解成多个子问题(节点),每个代表一个推理步骤
- 思维生成:在树的每个节点,生成多个可能的后续步骤(子节点)。通过提示LLM生成多个候选想法来实现
- 状态评估:设计一个评估函数(可以由LLM本身或外部工具实现)评估每个节点的质量或进展
- 搜索策略:决定如何遍历树。广度优先搜索(BFS)、深度优先搜索(DFS)、启发式搜索(根据评估分数选择最有希望的节点)
- 回溯机制:当路径被评估为无效或低质量时,能够回溯到父节点并尝试其他分支
- 路径整合:一旦找到满意的路径,将路径上的节点整合成最终答案
- 提示设计:为每个节点生成和评估步骤设计清晰的提示,确保LLM理解任务
- 并行探索:由于LLM的生成是独立的,可以同时探索多个路径以提高效率
- 验证和自洽:对最终答案进行验证,可能通过多个路径的答案投票(自洽)或外部验证
- 显式引导”多个想法”
2.7.2 为什么需要
链式思考(CoT)局限
- 线性单一路径:”一条路走到底”,第一步推理方向错误,答案很可能错误
- 缺乏全局视野:无法同时比较多种解决思路的优劣
- 无法回溯:一旦进入错误分支,无法退回尝试其他可能
ToT尤其适用
- 开放式复杂问题(如创意生成、策略规划)
- 需要多角度推理的问题(如数学证明、逻辑谜题)
- 答案不唯一,需择优的问题(如写作、决策分析)
2.7.3 应用场景
- 数学证明:同时尝试不同引理路径
- 创意写作:生成多个剧情分支,择优合并
- 策略游戏(如24点、象棋):探索不同走法组合
- 产品设计:提出多种方案并评估可行性
- 复杂决策:模拟不同选择的长短期影响
2.7.4 提示词举例
思维树提示法,将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估
https://github.com/dave1010/tree-of-thought-prompting
1 | // 常规方式,多角色假设 |
2.7.5 看看实际效果
基于上面的提示词学习,当我设定好基于思维树的提示词指令后,我让AI写一篇”修仙”的小说设定,可以看看下面的效果怎么样,是不是比较有特色了,这比”给我一个修仙小说大纲”的提示词输出的质量好多了。
1 | ### 修仙小说《灵根污染:天道自救录》生成报告 |
2.8 检索增强生成
(RAG, Retrieval-Augmented Generation)当前人工智能领域,尤其是大语言模型(LLM)应用中的一项核心技术。主要为了解决传统LLM存在的两大关键问题:知识局限性(过时、不全面) 和 “幻觉”(生成不准确或虚构信息)。
将传统的”生成式”模型与”检索式”系统相结合,先从外部知识库(如文档、数据库、网页等)中检索出与用户查询最相关的信息片段,然后将这些检索到的信息片段(作为”上下文”)和用户的原始查询一起输入给LLM,让LLM基于这些可靠的上下文信息来生成最终答案。
论文:https://arxiv.org/pdf/2005.11401
2.8.1 设计技巧
明确”来源优先”原则 防止模型无视检索内容自行发挥(仅根据以下内容回答,不要添加未提及的信息,如果检索内容中没有足够信息,请说明”信息不足”,不要猜测)
引导”逐步使用检索内容” (请逐条分析检索内容中哪些信息有用,并在推理中指出它们的作用。)
查询重写
1 | 任务:将用户查询重构为适合向量检索的形式 |
- 多向量检索
1 | ## 检索提示模板 |
2.8.2 为什么需要
解决知识局限性
- 动态更新: 只需更新向量数据库中的知识源,无需重新训练或微调
- 领域特定知识: 接入专有数据、内部文档或特定领域的知识库,让通用LLM变成领域专家
- 减少过时信息: 确保回答基于最新的可用数据
减少幻觉
- 基于证据生成:在检索到的真实信息上生成答案,大大降低了编造事实
- 可验证性: 答案通常可以追溯到检索到的源文档片段
提高答案质量和相关性
- 提供的上下文使 LLM 能更精准地理解查询意图,生成更相关、更具体、更符合要求的答案
成本效益
- 相比微调大型模型,构建和更新向量数据库的成本更低
模块化与灵活性
- 检索模块(向量数据库)和生成模块(LLM)可以独立优化和升级
2.8.3 应用场景
- 智能客服/问答系统: 基于产品文档、FAQ、客服记录回答用户问题
- 企业知识库助手: 员工查询公司政策、流程、项目文档、技术资料等
- 法律/金融/医疗等专业领域咨询: 基于法规、案例、研究报告、医学文献提供信息
- 研究辅助: 从大量论文或报告中检索相关信息并总结
- 内容摘要: 基于检索到的相关文本生成特定主题的摘要
- 增强搜索引擎: 提供直接、基于证据的答案片段,而非仅仅链接列表
2.8.4 提示词举例
1 | // 法律提示 |
2.9 方向性刺激
方向性刺激提示(Directional Stimulus Prompting) 是一种通过添加特定引导性信息(刺激信号)来控制大模型输出方向的技术。它通过激活模型内部相关知识路径,显著提升复杂任务的生成质量和可控性。
论文:https://arxiv.org/abs/2302.11520
核心原理:认知心理学视角
传统提示依赖任务描述(”写一首诗”),方向性刺激提示植入隐式认知线索,类似心理学中的”启动效应”(Priming Effect):
1 | // 普通提示 |
刺激信号:”学术期刊审稿人”+”批判视角”+”三个突破点” 激活模型对应的知识结构和表达范式
2.9.1 设计技巧
- 角色刺激 你是一名,高盛顶级分析师
- 框架刺激 以此结构推导,数据观察 → 模式识别 → 归因分析 → 行动建议
- 对比刺激 通过否定表述强化目标特征,生成创新方案时:避免常规方法(如A/B测试)
- 时空锚定 站在5年后的时间节点,评估特斯拉规模情况
- 感官刺激 描述产品体验时调用多感官词汇。视觉:流光紫机身折射霓虹,触觉:陶瓷背板温润如脂;禁用抽象形容词(如”高端””优雅”)
- 情感基调刺激 输出需承载情感基调,主基调:危机感(权重0.7),次基调:希望感(权重0.3)示例词汇,危机感:悬崖边缘;希望感:曙光
- 避免刺激冲突 避免同时激活矛盾角色(“激进投资人”与”保守审计师”)
- 避免过度刺激 过多限制导致输出僵化,可以保留一定的自由生成空间
2.9.2 为什么需要
- 认知资源聚焦(减少71%无关输出)
- 领域适应性提升
- 突破模型知识局限
- 创造性质变
- 语义控制精度跃升
- 多模态协同增效
2.9.3 应用场景
- 可以说是标配,几乎所有场景都能覆盖到
2.9.4 提示词举例
1 | // 综合刺激 |
2.10 程序辅助语言模型
程序辅助语言模型(PAL)是一种将自然语言推理与程序执行深度融合的提示工程技术,通过生成可执行代码代替直接输出答案,彻底解决大语言模型在数学计算、符号推理等任务中的固有缺陷
论文:https://arxiv.org/abs/2211.10435
核心原理(解耦推理与计算)
传统LLM处理数学问题时直接生成答案(易出错),而PAL要求模型输出可执行代码片段,由外部解释器运行获得结果:
1 | // 什么编程语言代码都行,python只是举例 |
2.10.1 设计技巧
- 明确要求生成代码 在提示词中明确指出需要生成代码,并指定代码语言
- 提供清晰的步骤说明 将问题分解为步骤,并让模型按照步骤生成代码
- 指定输出格式 要求模型将代码放在特定的标记内以便提取
- 强调关键要求 比如要求代码必须包含打印结果的语句
- 处理边界条件和错误 提示模型考虑可能的边界情况,并添加必要的错误处理
- 利用注释引导 在生成的代码中,要求模型添加注释,说明每一步的作用,这有助于提高代码的可读性和正确性
- 指定所需的库 如果需要使用外部库,在提示词中明确说明
- 提供 Few-shot 示例 加入1~2个”问题 → 程序思考 → 结果”示例,可显著提升表现
2.10.2 为什么需要
- 传统LLM处理数学问题时直接生成答案(易出错)
- 突破语言模型计算局限
- 安全性与可控性倍增
- 复杂任务结构化分解
- 跨领域知识无缝整合
2.10.3 应用场景
- 符号数学计算 求函数
f(x)=x²+2x 在x=3处的导数,如果直接让大模型给结果可能错误,但是给出执行程序答案几乎是100%正确。 - 金融复利计算
10年每年投资10000元,年化收益5%,求终值 - 物理仿真
计算质量为2kg的物体从10m高度自由落体的落地速度(g=9.8)
2.10.4 提示词举例
1 | 请编写Python代码解决以下问题: |
2.11 自我反思
自我反思(Reflexion)旨在赋予大语言模型(LLM)动态评估自身行为、识别错误并主动修正的能力。
超越了传统”生成即结束”的范式,使AI具备类似人类的迭代式学习与错误修复机制,显著提升复杂任务中的鲁棒性。
论文:https://arxiv.org/pdf/2303.11366
2.11.1 设计技巧
- 结构化提问模板,建立检查清单(目标精准度/提示词漏洞/信息效率/约束有效性)
- 反思→行动的即时转化,将反思结论直接翻译为提示词修改动作(保存提示词版本+对应输出结果,标注修改点)
- 认知升级技巧:挑战隐含假设(定期追问”我默认了什么不该默认的前提? “)
- 将反思转化为肌肉记忆 每完成几次迭代,就反思一次(如果重写这个提示词,我会立刻做的第一处修改是__,因为上次反思中我发现__)
- 明确引导反思维度 明确说明要反思哪里
- 鼓励批判性思维用语 有没有我忽略的边缘情况?我有没有做过任何隐藏的假设?
- Few-shot 示例引导反思风格 (提供一个”错误→反思→更正”的示范,效果会更好)
2.11.2 为什么需要
- 建立可解释的AI协作逻辑
- 加速提示优化:从试错到模式复用
- 看见自己的思维盲区
- 提示工程反哺核心能力
2.11.3 应用场景
- 编程助手:生成代码 → 运行测试 → 发现错误 → 修正并重新编译
- 科学计算:求解方程 → 验证解合理性(如边界条件)→ 调整数值方法
- 决策支持:输出投资建议 → 检查是否违反风险约束 → 重新平衡资产组合
- 内容创作:撰写市场报告 → 检测数据矛盾 → 补充来源或修正结论
2.11.4 提示词举例
- 反思提示模板:结构化指令引导LLM自我批判(”请检查以下代码是否存在语法错误?”)
- 验证工具:自动化测试结果(如单元测试、符号验证)
- 外部反馈器:人工反馈或规则引擎标记错误(如合规性检查)
- 记忆存储:记录错误模式避免重蹈覆辙(”上次因忽略时区导致会议安排失败”)
1 | // 简单使用 |
2.12 多模态CoT提示
多模态 CoT(思维链)提示,是将传统文本推理链扩展至图像、音频、视频等多模态数据的技术,通过引导模型对视觉/听觉信息进行逐步推理,解决复杂跨模态任务的幻觉问题。
核心原理
常规 CoT 仅处理文本序列(问题 → 推理步骤 → 答案),而多模态 CoT 增加跨模态对齐与联合推理,将图片/视频/文本等内容对其联合推理。
例如
- 特征绑定:将图像区域与文本描述关联(”图中穿红衣服的人 → ‘嫌疑人A’”)
- 时序推理:视频场景中分解动作序列(如 “伸手 → 拿刀 → 刺向 → 流血”)
论文:https://arxiv.org/abs/2302.00923
文献:https://arxiv.org/abs/2302.14045
2.12.1 设计技巧
- 文本推理 → 锚定逻辑框架
- 视觉感知 → 注入空间关系
- 时序信号 → 捕捉动态变化
- 明确视觉内容类型,图,图表,截图
- 强化逐步思考习惯(”Step-by-step”标记)
- 拆解任务结构,引导从”看”到”想”
- 关键技巧:用文本指令明确三者的协作规则(”先看图描述事件→再用时间轴分析原因→最后用数据验证”)
2.12.2 为什么需要
- 培养AI的”常识”
- 解决”纸上谈兵”问题,更多的结合现实,视觉/听觉/时空
- 让AI真正”眼脑并用”
1 | 文本:"他愤怒地摔门而去" |
2.12.3 应用场景
- 医疗影像诊断
- 工业质检
- 教育解题(数学+几何图)
2.12.4 提示词举例
1 | [图像]:电路板焊接点 |
2.13 ReAct 框架
ReAct(Reasoning + Acting)通过让大语言模型(LLM)交替执行”思考-行动-观察”的循环,将推理过程与工具调用动态结合的提示工程框架,解决复杂任务中的幻觉和推理错误问题。
论文:https://arxiv.org/abs/2210.03629
核心内容
ReAct 模拟人类”边思考边行动”模式:
- 推理(Reasoning):LLM 生成当前步骤的思考(如问题拆解、策略规划)
- 行动(Acting):根据思考调用外部工具(如搜索引擎、API)
- 观察(Observation):获取工具返回的结果,作为下一步推理的依据
2.13.1 设计技巧
- 强制”怀疑-验证”机制
1 | **模板**: |
2.13.2 为什么需要
| 优势 | 劣势 |
|---|---|
| 减少幻觉:依赖实时数据而非记忆 | 长链任务易出错(错误累积) |
| 支持多跳推理(如”A影响B,B导致C”) | 环境依赖强(API故障则失效) |
| 可解释性强:全程步骤可追溯 | 计算开销大(多次调用LLM+工具) |
2.13.3 应用场景
- 知识密集型问答,动态检索最新信息(结合维基百科API验证事实)
- 决策支持系统,电商场景:用户查询”性价比最高的无线耳机”→ ReAct调用价格API+产品评测库
- 自动化流程,企业级应用:监控系统异常 → 检索日志 → 生成诊断报告 → 触发修复工单
2.13.4 提示词举例
注:行动需用Action[参数]格式,便于解析器识别,提示词模板,尽量包含少样本示例
1 | 问题:苹果遥控器最初是为哪个设备设计的? |
2.14 自动推理并使用工具 (ART)
让大语言模型(LLM)像人类一样主动规划推理步骤、调用外部工具来解决复杂问题。它代表了智能体(Agent)能力的重大突破。
核心内容
ART 核心是赋予LLM “自主使用工具” 的能力
- 分解复杂问题:将用户复杂查询拆解为多步骤推理任务
- 动态选择工具:根据任务需求调用合适的工具(如计算器、搜索引擎、代码解释器、API等)
- 自动化执行:自动运行工具并解析结果
- 验证与迭代:检查结果有效性,必要时修正错误或重新规划步骤
关键突破:让LLM从”纯文本生成器”升级为”具备执行能力的推理引擎”
2.14.1 设计技巧
- 引导”工具选择”作为推理的一部分(这个问题无法仅通过已有知识解决,我需要查询最新数据)
- 设计清晰的工具接口格式
1 | 你可以使用以下工具: |
- 鼓励多轮推理与信息整合
1 | Observation: 查到某地人口为800万。 |
2.14.2 为什么需要
- 解决复杂问题:突破模型自身限制(如数学计算弱、知识滞后),通过工具扩展能力边界
- 动态适应性强 根据中间结果实时调整策略,应对不确定性
- 结果可验证 工具输出具备客观性(如代码执行结果),减少”幻觉”
- 模块化扩展 工具库可自由增删(如接入企业内部API、数据库),无需重新训练模型
2.14.3 应用场景
- 科学计算:自动调用 Python 求解微分方程、可视化数据
- 实时决策:结合 股票API + 新闻分析工具 生成投资建议
- 自动化办公:解析邮件→提取任务→调用日历API安排会议→生成回复
- 跨领域问答:先搜索医学论文 → 再用统计工具分析数据 → 生成诊疗建议
- 代码生成与调试:写代码 → 执行测试 → 根据报错修正 → 输出最终版本
2.14.4 提示词举例
1 | 你是一位具备自主推理和工具使用能力的AI助手,可以根据任务自由决定思考路径和使用的工具。 |
三、一些官方提示模板
https://api-docs.deepseek.com/zh-cn/prompt-library/
3.1 Deepseek官方的”模型提示词生成”的提示词:
这里面包含上面的几点内容:指令(四条指令要求),上下文(你是大模型专家等等),输出格式(markdown),输入内容(User输入),样本示例(少量样本);在样本示例中又采用了 “##”的格式来表达指令。
3.2 github 各类官方提示
https://github.com/x1xhlol/system-prompts-and-models-of-ai-tools
3.3 anthropic官方
https://colab.research.google.com/drive/1SoAajN8CBYTl79VyTwxtxncfCWlHlyy9
3.4 提示工程
https://www.promptingguide.ai/prompts
3.5 explainthis
https://www.explainthis.io/zh-hans/chatgpt
3.6 chatgpt 调教指南
https://github.com/PlexPt/awesome-chatgpt-prompts-zh?tab=readme-ov-file
https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
3.7 AI飞升社区
https://aifeisheng.com/thread-364.htm
四、知识来源
https://www.promptingguide.ai/
https://github.com/yunwei37/Prompt-Engineering-Guide-zh-CN
https://www.explainthis.io/zh-hans/ai/prompt-engineering
https://docs.anthropic.com/zh-CN/docs/build-with-claude/prompt-engineering/overview
https://python.langchain.com.cn/docs/use_cases







