Screenpipe 介绍
https://github.com/mediar-ai/screenpipe
Screenpipe 自动记录下你在屏幕上看到的内容,并生成视频和音频以及本地数据库数据,最关键的是,有了数据库,就能让这些记录变得完全可查找。
- 24/7 媒体捕获:连续捕获屏幕和音频数据
- 个性化人工智能:直接接入本地/在线大模型,能够让 AI 对捕获的数据进行总结
- 开源且安全:数据保持私密完全本地化
- 跨平台:支持 Windows、MacOS 和 Linux
- 多设备支持:支持多个显示器和音频设备,实现全面的数据捕获
- 插件:允许在 NextJS 中创建和使用插件,在沙盒运行时中运行以扩展功能
电脑配置要求
最低要求
- 双核处理器(2GHz+)
- 2GB 内存
- 20GB 可用磁盘空间
- 任何用于硬件加速的现代显卡
推荐规格
- 四核处理器或更高
- 4GB+内存
- 50GB+ 可用 SSD 空间
- 至少有 2GB VRAM 的专用显卡
- screenpipe 经过优化,可以使用硬件加速,从而显著降低 CPU 使用率
这个配置要求,可以说非常低了,虽然推荐配置要求 2GB 显存的显卡,但是一般核显电脑也没问题,做了一组数据测试,一小时录制,大概视频和音频产生数据,290M,一天按照8小时使用电脑时间,大概是2.3G数据(多数人应该不必全天候录制)。
核心技术
- 持续屏幕捕获,定期截取屏幕画面,形成一个视觉上的“时间流”,每张图会成为视频的一帧画面
- 强大的OCR识别,Screenpipe 自动对屏幕截图进行OCR识别,提取画面中的所有文本内容
- 智能索引,将识别出的文本与对应的屏幕画面关联起来,建立一个高效的本地索引数据库
安装使用
该项目虽然有14k的star,但是还是一个高速发展的项目,变化较快,而且完整的GUI图形界面是收费的,想要免费使用需要使用cli版本,或者直接下载构建exe版本。
下载
1 | iwr get.screenpi.pe/cli.ps1 | iex |
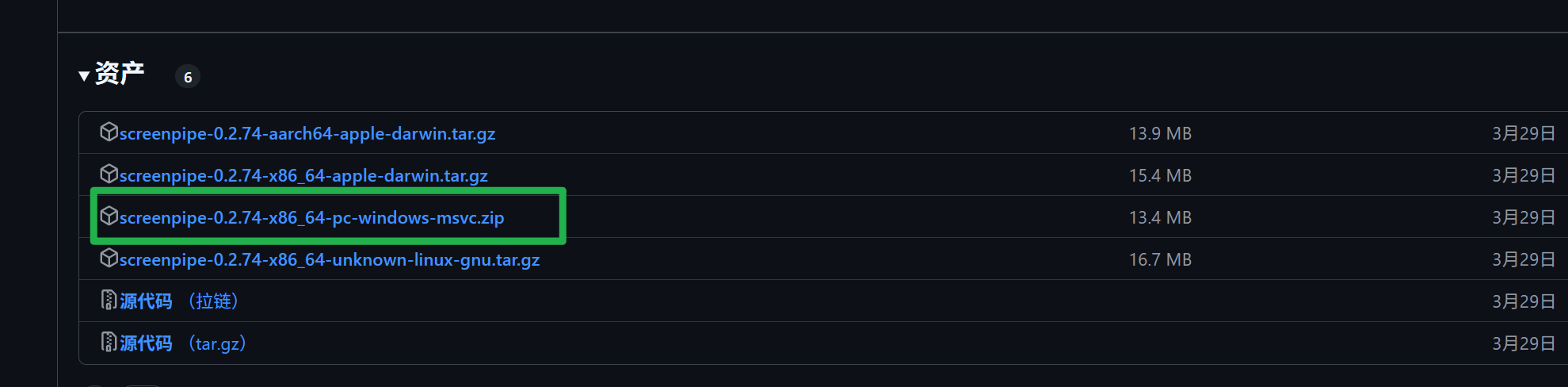
安装
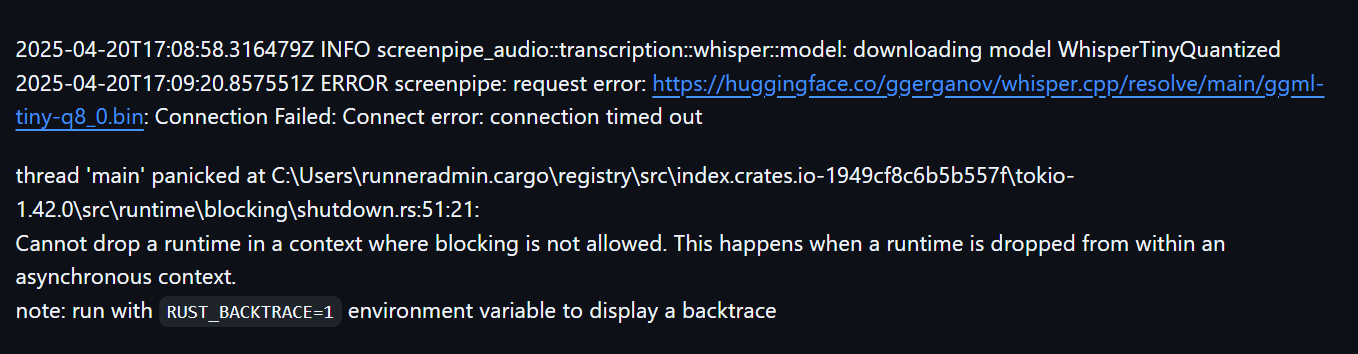
完成下载后,解压文件,里只有两个文件,其中一个是exe文件,多数人应改无法正常安装,需要huggingface的镜像,因为初次启动要从huggingface下载内容,国内无法访问,所以要用他的镜像源。
错误截图
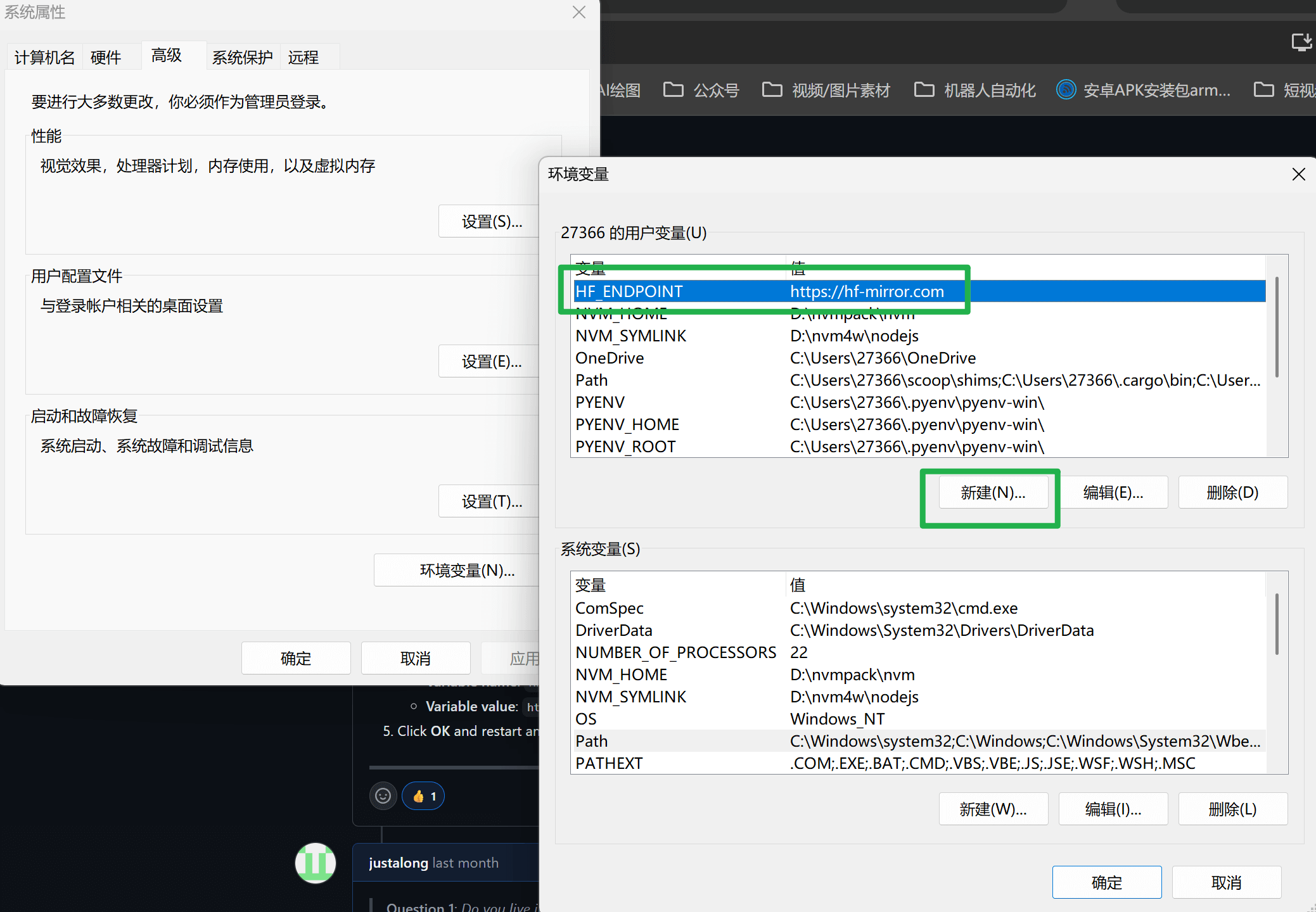
命令行修改镜像源
1 | // cmd命令行设置 |
直接使用系统设置修改,也可以通过win + S => 搜索环境变量 => 设置上面内容,无论哪种,需要重启一下电脑。
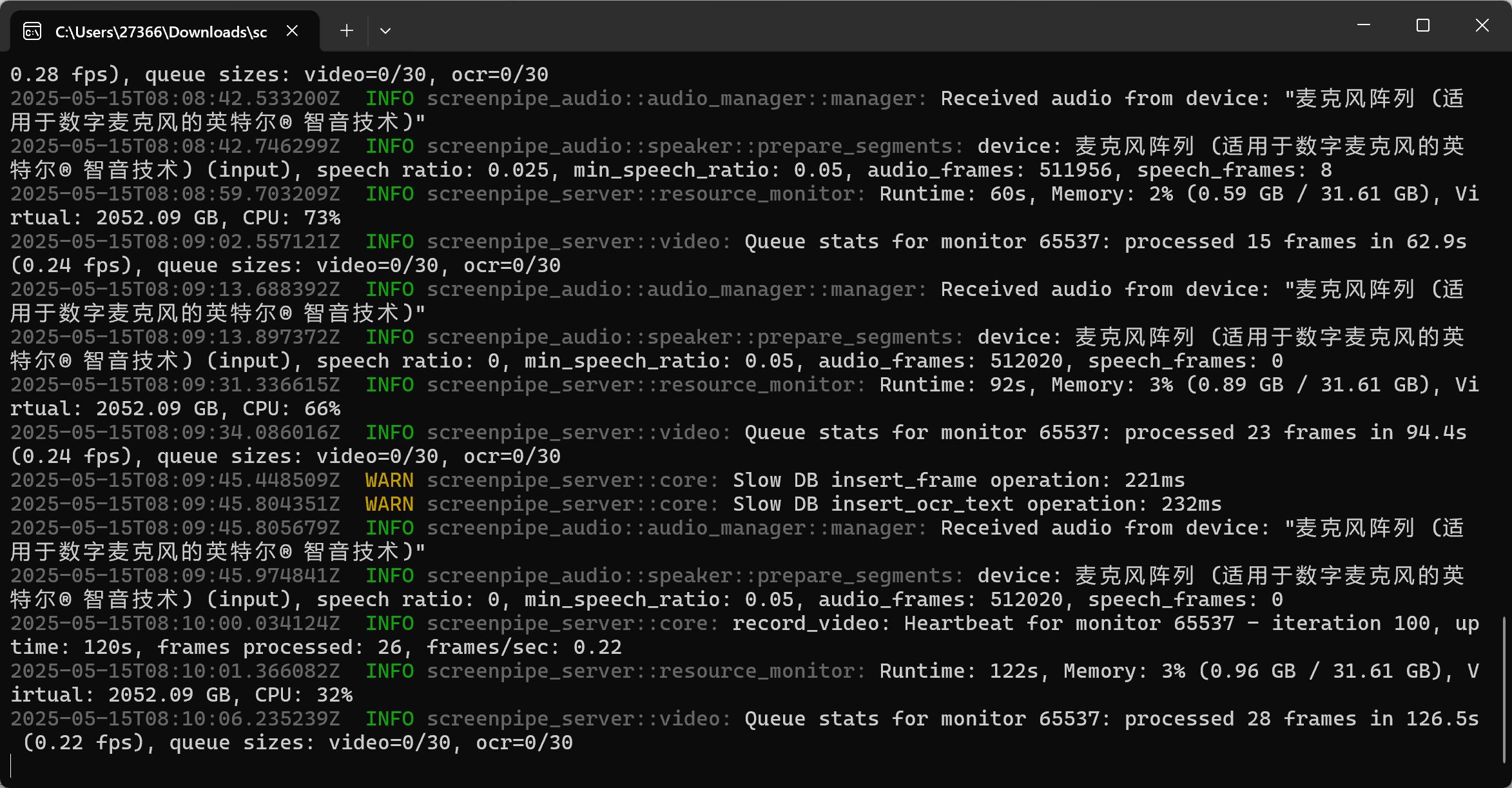
使用

重启电脑后,直接双击exe文件,即可启动,启动效果如下。默认生成的数据都在 C:\Users\你的用户名.screenpipe\data下面,可以通过设置更改,详细参考文档里的cli部分。
支持AI大模型搜索
本地大模型,非常吃电脑,低配置电脑不用玩这个了,使用在线大模型,需要接入Token,各家大模型的Token都是计费的,如果不想花钱,也不用试了。
如果你是非常依赖这个能能力的用户,并且收益对个人非常打, 建议直接使用官方付费版本, 有稳定更新和维护,图形界面可以快速支持插件,大模型接入等。
如果你是开发者,且电脑配置不错,可以通过ollama本地大模型完成接入,利用screenpipe官方提供Node版本SDK,或者通过screenpipe的本地启动端口3030来链接数据库,自己完成二次开发。
适用人员
几乎所有长时间使用电脑的用户都能从中获益
- 开发者,快速找回之前看到的错误信息、代码片段、终端输出
- 设计师,查找参考图中的文字,图片
- 研究人员/学生,轻松捕获在线课程、电子书、论文中的关键文字和图表
- 客服,快速找回客户反馈的信息







